说明
Terraform:HashiCorp Terraform是一个IT基础架构自动化编排工具,可以用代码来管理维护IT资源。它编写了描述云资源拓扑的配置文件中的基础结构,例如虚拟机、存储账户和网络接口。其就是高度标准化。
Terraform代码规范
推荐以下代码规范:
- 使用两个空格缩进
- 同一缩进层级的多个赋值语句以等号对齐:
- 当块体内同时有参数赋值以及内嵌块时,请先编写参数赋值,然后是内嵌块。参数与内嵌块之间空一行分隔;
- 对于同时包含参数赋值以及元参数赋值的块,请先编写元参数赋值语句,然后是参数赋值语句,之间空一行分隔。元参数块请置于块体的最后,空一行分隔:
- 顶层块之间应空一行分隔。内嵌块之间也应该空一行分隔,除非是相同类型的内嵌块(比如resource块内部多个provisioner块)
1 | resource "aws_instance" "example" { |
Terraform 基础概念
Provider
Terraform被设计成一个多云基础设施编排工具,不像CloudFormation那样绑定AWS平台,Terraform可以同时编排各种云平台或是其他基础设施的资源。Terraform实现多云编排的方法就是Provider插件机制。

Provider 缓存机制
默认情况下,当完成 terraform init 之后,项目文件夹中就会创建.terraform文件夹,并且会下载Provider的相关插件。
1 | .terraform |
有的时候下载某些Provider会非常缓慢,或是在开发环境中存在许多的Terraform项目,每个项目都保有自己独立的插件文件夹非常浪费磁盘,这时我们可以使用插件缓存。有两种方式可以启用插件缓存:
第一种方法是配置TF_PLUGIN_CACHE_DIR这个环境变量:
1 | export TF_PLUGIN_CACHE_DIR="$HOME/.terraform.d/plugin-cache" |
第二种方法是使用CLI配置文件:
1 | plugin_cache_dir = "$HOME/.terraform.d/plugin-cache" |
同时需要注意的是,Terrafom引擎永远不会主动删除缓存文件夹中的插件,缓存文件夹的尺寸可能会随着时间而增长到非常大,这时需要手工清理。
Provider的声明
一组Terraform代码要被执行,相关的Provider必须在代码中被声明。不少的Provider在声明时需要传入一些关键信息才能被使用。不同的Provider所需要的关键信息也是不尽相同的,因此这里需要注意一下。
1 | terraform { |
这里一部分的HCL(HashiCorp Configuration Language)也说明了如何进行声明一个Provider。
required_providers 所需要的providers版本
ucloud,声明了本段代码必须要名为ucloud的Provider才可以执行。
source = “ucloud/ucloud”,这一行声明了ucloud这个插件的源地址(Source Address)。一个源地址是全球唯一的,它指示了Terraform如何下载该插件。
version = “>=1.24.1”,声明了该源码所需要的插件的版本约束。
provider,不同的provider所需要使用的关键词信息是不同的
ucloud
1 | provider "ucloud" { |
aws
1 | provider "aws" { |
Aliyun
1 | access_key = "access_key" |
多Provider实例
一个Local Name是在一个模块中对一个Provider的唯一的标识。可以声明多个同类型的Provider,并给予不同的Local Name,也就是同时操作多个云资源环境。这使得我们可以在一组配置文件中同时操作不同区域、不同账号的资源。
这里提供了两种方式协助我们使用多Provider实例:
- 指明Provider key
- Alias 别名
显视指明Provider Local Name
1 | terraform { |
使用
1 | # Use Provider Local Name |
例如上面的例子,声明了两个UCloud Provider,分别定位在北京区域和上海区域。在接下来的data声明中显式指定了provider的Local Name
Alias别名
1 | terraform { |
使用
1 | data "ucloud_security_groups" "default" { |
这里的required_providers中只声明了一次ucloud,并且在data中指定provider时传入的是ucloud.ucloudsh。多实例Provider请使用别名。
状态管理
使用backend字段对状态文件进行存储
1 | terraform { |
Terraform 将需要目标后端存储桶上的以下 AWS IAM 权限:
s3:ListBucketonarn:aws:s3:::mybuckets3:GetObjectonarn:aws:s3:::mybucket/path/to/my/keys3:PutObjectonarn:aws:s3:::mybucket/path/to/my/keys3:DeleteObjectonarn:aws:s3:::mybucket/path/to/my/key
policy如下所示
1 | { |
Terraform 代码编程
数据类型
原始类型分三类:string、number、bool。
- string,代表一组Unicode字符串,例如:
"hello"。 - number,代表数字,可以为整数,也可以为小数。
- bool,代表布尔值,要么为
true,要么为false。bool值可以被用做逻辑判断。 - null,在条件表达式中非常有用,你可以在某项条件不满足时跳过对某参数的赋值。
数据格式转换
隐式转换
number和bool都可以和string进行隐式转换,当我们把number或bool类型的值赋给string类型的值,或是反过来时,Terraform会自动替我们转换类型。
数据结构
Terraform支持三种数据结构:列表、映射类型、集合类型;
list:列表是一组值的连续集合,可以用下标访问内部元素,下标从0开始。例如名为l的list,l[0]就是第一个元素。list类型的声明可以是list(number)、list(string)、list(bool)等,括号中的类型即为元素类型。
map:字典类型(或者叫映射类型),代表一组键唯一的键值对,键类型必须是string,值类型任意。map(number)代表键为string类型而值为number类型,其余类推。map值有两种声明方式,一种是类似{"foo": "bar", "bar": "baz"},另一种是{foo="bar", bar="baz"}。键可以不用双引号,但如果键是以数字开头则例外。多对键值对之间要用逗号分隔,也可以用换行符分隔。推荐使用=号(Terraform代码规范中规定按等号对齐,使用等号会使得代码在格式化后更加美观)
set:集合类型,代表一组不重复的值。
语法结构
Count—循环结构
定义count
count参数可以是任意自然数,Terraform会创建count个资源实例,每一个实例都对应了一个独立的基础设施对象,并且在执行Terraform代码时,这些对象是被分别创建、更新或者销毁的:
1 | resource "aws_instance" "server" { |
在Resource块中的表达式里使用count对象来获取当前的count索引号,count对象只有一个属性count.index,代表当前对象对应的count下标索引(从0开始)。
访问count
如果一个Resource块定义了count参数,那么Terraform会把这种多资源实例对象与没有count参数的单资源实例对象区别开。
- 访问单资源实例对象:
<TYPE>.<NAME>(例如:aws_instance.server) - 访问多资源实例对象:
<TYPE>.<NAME>[<INDEX>](例如:aws_instance.server[0],aws_instance.server[1])
for_each—循环结构
for each的参数可以是一个map或者set,Terraform会为集合中的每一个元素都创建一个独立的资源对象。
使用map
1 | resource "azurerm_resource_group" "rg" { |
使用set(string)
1 | resource "aws_iam_user" "the-accounts" { |
可以在声明了for_each参数的resource块内使用each对象来访问当前的迭代器对象:
each.key:map的键,或是set中的值each.value:map的值,或是set中的值
访问属性
当一个resource声明了for_each时,Terraform会把这种多资源实例对象与没有count参数的单资源实例对象区别开:
- 访问单资源实例对象:
<TYPE>.<NAME>(例如:aws_instance.server) - 访问多资源实例对象:
<TYPE>.<NAME>[<KE>](例如:aws_instance.server["ap-northeast-1"],aws_instance.server["ap-northeast-2"])
配置语法
参数
参数赋值就是将一个值赋给一个特定的名称:
1 | image_id = "abc123" |
等号前的标识符就是参数名,等号后的表达式就是参数值。参数赋值时Terraform会检查类型是否匹配。参数名是确定的,参数值可以是确定的字面量硬编码,也可以是一组表达式,用以通过其他的值加以计算得出结果值。
块(Block)
一个块是包含一组其他参数的容器,例如:
1 | resource "aws_instance" "example" { |
块由块类型、块标签和块主体构成,上面例子中的
- 块类型:resource
- 块标签:aws_instance
- 块主题:example
注释
Terraform支持三种注释:
#单行注释,其后的内容为注释//单行注释,其后的内容为注释/*和*/,多行注释,可以注释多行
默认情况下单行注释优先使用#。自动化格式整理工具会自动把//替换成#。
输入变量
如果我们把一组Terraform代码想像成一个函数,那么输入变量就是函数的入参。输入变量用variable块进行定义:
1 | variable "image_id" { |
在同一个Terraform模块中的变量名必须是唯一的,可以在代码中通过var.<Name>来进行引用。输入变量只能在声明该变量的目录下的代码中使用,输入变量块中可以定义一些属性。
类型
可以在输入变量块中通过type定义类型,例如:
1 | variable "name" { |
定义了类型的输入变量只能被赋予符合类型约束的值。
默认值
默认值定义了当Terraform无法获得一个输入变量得到值的时候会使用的默认值。例如:
1 | variable "name" { |
当Terraform无法通过其他途径获得name的值时,var.name的值为"John Doe"
描述
可以在输入变量中定义一个描述,简单地向调用者描述该变量的意义和用法:
1 | variable "image_id" { |
如果在执行terraform plan或是terraform apply时Terraform不知道某个输入变量的值,Terraform会在命令行界面上提示我们为输入变量设置一个值。例如上面的输入变量代码,执行terraform apply时:
断言
通过断言来约束输入输入变量是否符合规范。
1 | variable "image_id" { |
Condition参数是一个bool类型的参数,我们可以用一个表达式来定义如何界定输入变量是合法的。当contidion为true时输入变量合法,反之不合法。condition表达式中只能通过var.\引用当前定义的变量,并且它的计算不能产生错误。
对输入变量赋值
命令行参数
对输入变量赋值有几种途径,一种是在调用terraform plan或是terraform apply命令时以参数的形式传入:
1 | $ terraform apply -var="image_id=ami-abc123" |
可以在一条命令中使用多个-var参数。
参数文件
第二种方法是使用参数文件。参数文件的后缀名可以是.tfvars或是.tfvars.json。.tfvars文件使用HCL语法,.tfvars.json使用JSON语法。
以.tfvars为例,参数文件中用HCL代码对需要赋值的参数进行赋值,例如:
1 | image_id = "ami-abc123" |
后缀名为.tfvars.json的文件用一个JSON对象来对输入变量赋值,例如:
1 | { |
调用terraform命令时,通过-var-file参数指定要用的参数文件,例如:
1 | terraform apply -var-file="testing.tfvars" |
交互界面传值
在前面介绍断言的例子中我们看到过,当我们从命令行界面执行terraform操作,Terraform无法通过其他途径获取一个输入变量的值,而该变量也没有定义默认值时,Terraform会进行最后的尝试,在交互界面上要求我们给出变量值.
输入变量赋值优先级
当上述的赋值方式同时存在时,同一个变量可能会被赋值多次。Terraform会使用新值覆盖旧值。
Terraform加载变量值的顺序是:
- 环境变量
terraform.tfvars文件(如果存在的话)terraform.tfvars.json文件(如果存在的话)- 所有的
.auto.tfvars或者.auto.tfvars.json文件,以字母顺序排序处理 - 通过
-var或是-var-file命令行参数传递的输入变量,按照在命令行参数中定义的顺序加载
假如以上方式均未能成功对变量赋值,那么Terraform会尝试使用默认值;对于没有定义默认值的变量,Terraform会采用交互界面方式要求用户输入一个。对于某些Terraform命令,如果执行时带有-input=false参数禁用了交互界面传值方式,那么就会报错。
输出变量
输出值的声明
输出值的声明使用输出块,例如:
1 | output "instance_ip_addr" { |
output关键字后紧跟的就是输出值的名称。在当前模块内的所有输出值的名字都必须是唯一的。output块内的value参数即为输出值,它可以像是上面的例子里那样某个resource的输出属性,也可以是任意合法的表达式。
输出值只有在执行terraform apply后才会被计算,光是使用terraform plan并不会计算输出值。
Terraform代码中无法引用本目录下定义的输出值。
description
1 | output "instance_ip_addr" { |
与输入变量的description类似,我们不再赘述。
depends_on
在同一个 Terraform 配置文件中可以包含多个资源。通过在资源中引用其他资源的属 性值,Terraform可以自动推断出资源的依赖关系。然而,某些资源的依赖关系对于 Terraform是不可见的,这就需要使用 depends_on 来创建显式依赖。我们可以使用 depends_on 来更改资源的创建顺序或执行顺序,使其在所依赖资源之后处理。 depends_on 的表达式是依赖资源的地址列表。
例如我们在远程操作一台ECS服务器之 前,需要为其绑定EIP或配置NAT规则。
1 | output "instance_ip_addr" { |
局部值
有时我们会需要用一个比较复杂的表达式计算某一个值,并且反复使用之,这时我们把这个复杂表达式赋予一个局部值,然后反复引用该局部值。如果说输入变量相当于函数的入参,输出值相当于函数的返回值,那么局部值就相当于函数内定义的局部变量。
局部值通过locals块定义,例如:
1 | locals { |
一个locals块可以定义多个局部值,也可以定义任意多个locals块。赋给局部值的可以是更复杂的表达式,也可以是其他data、resource的输出、输入变量,甚至是其他的局部值:
1 | locals { |
引用局部值的表达式是local.<NAME>(注意,虽然局部值定义在locals块内,但引用是务必使用local而不是locals),例如:
1 | resource "aws_instance" "example" { |
PS:局部值只能在同一模块内的代码中引用。可以将局部值理解为函数,可以重复调用局部值,这样子就无需多次编写重复复杂的表达式,提升代码的可读性。
资源
资源是Terraform最重要的组成部分,而本节亦是本教程最重要的一节。资源通过resource块来定义,一个resource可以定义一个或多个基础设施资源对象,例如VPC、虚拟机,或是DNS记录、Consul的键值对数据等。
一个Resource代表了想要创建的基础设施建设。每当Terraform按照一个resource块创建了一个新的基础设施对象,这个实际的对象的id会被保存进Terraform状态中,使得将来Terraform可以根据变更计划对它进行更新或是销毁操作。
资源语法
其中的web指的就是local name,值得注意的是,同一模块内同一资源类型的Local Name是不允许的。例如,下面这种编码方式是不允许的。
1 | resource "aws_instance" "web" { |
但是同一模块内的不同资源允许同名
1 | resource "aws_instance" "web" { |
元参数声明:
- depends_on:显式声明依赖关系
- count:创建多个资源实例
- for_each:迭代集合,为集合中每一个元素创建一个对应的资源实例
- provider:指定非默认Provider实例
- lifecycle:自定义资源的生命周期行为
- provisioner 和 connection:在资源创建后执行一些额外的操作
depends_on
terraform可以知道资源的显性依赖环境。但是有些逻辑层面的隐藏依赖环境,terraform是不知道的,因此则需要我们手动去指定资源之间的关系。即当资源间确实存在依赖关系,但是彼此间又没有数据引用的场景下才有必要使用depends_on。
使用depends_on的例子是这样的:
1 | # 声明了一个AWS IAM角色 |
从上面的terraform代码可以整理出以下的创建资源逻辑图

按照terraform的显性逻辑可以推出上面这一逻辑图,但是这个逻辑中存在一个问题,即aws_instance与aws_iam_role_policy是同时创建的并没有先后顺序。但是存在某些因素导致instance先于aws_iam_role_policy创建出来,则会导致报错,因此正确的逻辑图应该如下图所示。

依靠terraform显性逻辑无法将aws_iam_role_policy与aws_instance联系起来,因此则需要我们手动将这两个因素联系起来。即通过depends_on这个参数
1 | resource "aws_instance" "example" { |
判定隐形逻辑:
需要将资源之间的逻辑图导出,保证逻辑图闭环。
provisioner 和 connection
todo
访问资源输出属性
在表达式中引用资源属性的语法是<RESOURCE TYPE>.<NAME>.<ATTRIBUTE>。
数据源data
数据源允许查询或计算一些数据以供其他地方使用。使用数据源可以使得Terraform代码使用在Terraform管理范围之外的一些信息,或者是读取其他Terraform代码保存的状态。每一种Provider都可以在定义一些资源类型的同时定义一些数据源。
使用数据源
数据源通过一种特殊的资源访问:data资源。数据源通过data块声明:
1 | data "aws_ami" "example" { |
一个data块请求Terraform从一个指定的数据源aws_ami读取指定数据并且把结果输出到Local Name为example的实例中。
查询条件
因为数据源是通过查询云端的资源得到的,因此可以通过查询条件进行查询我们所需要查询的资源.在上述例子中,most_recent、owners和tags都是定义查询aws_ami数据源时使用的查询条件。
数据源的依赖关系
数据源有着与资源一样的依赖机制,我们也可以在data块内设置depends_on元参数来显式声明依赖关系,在此不再赘述。
多数据源实例
与资源一样,数据源也可以通过设置count、for_each元参数来创建一组多个数据源实例,并且Terraform也会把每个数据源实例单独创建并读取相应的外部数据,对count.index与each的使用也是一样的,在count与for_each之间选择的原则也是一样的。
指定特定Provider实例
同资源一样,数据源也可以通过provider元参数指定使用特定Provider实例,在此不再赘述。
生命周期
同资源不一样,数据源目前不可以通过设置lifecycle块来定制化生命周期,但数据源内部lifecycle被设置为保留关键字以备将来可以支持该功能。
demo
定义
一个数据源定义例子如下:
1 | # Find the latest available AMI that is tagged with Component = web |
引用
引用数据源,引用数据源数据的语法是data.<TYPE>.<NAME>.<ATTRIBUTE>:
1 | resource "aws_instance" "web" { |
表达式
todo
terraform module
todo
terraform command
环境变量
Terraform使用一系列的环境变量来定制化各方面的行为。如果只是想简单使用Terraform,我们并不需要设置这些环境变量。以下介绍常用的环境变量
TF_LOG
该环境变量可以设定Terraform内部日志的输出级别,例如:
1 | export TF_LOG=TRACE |
Terraform日志级别有TRACE、DEBUG、INFO、WARN和ERROR。TRACE包含的信息最多也最冗长,如果TF_LOG被设定为这五级以外的值时Terraform会默认使用TRACE。
TF_LOG_PATH
该环境变量可以设定日志文件保存的位置。注意,如果TF_LOG_PATH被设置了,那么TF_LOG也必须被设置。举例来说,想要始终把日志输出到当前工作目录,我们可以这样:
1 | export TF_LOG_PATH=./terraform.log |
TF_INPUT
该环境变量设置为”false”或”0”时,等同于运行terraform相关命令行命令时添加了参数-input=false。如果你想在自动化环境下避免Terraform通过命令行的交互式提示要求给定输入变量的值而是直接报错时(无default值的输入变量,无法通过任何途径获得值)可以设置该环境变量:
1 | export TF_INPUT=0 |
TF_VAR_name
1 | export TF_VAR_region=us-west-1 |
可以通过设置名为TF_VAR_name的环境变量来为名为”name”的输入变量赋值.
TF_CLI_ARGS以及TF_CLI_ARGS_name
TF_CLI_ARGS的值指定了附加给命令行的额外参数,这使得在自动化CI环境下可以轻松定制Terraform的默认行为。
该参数的值会被直接插入在子命令后(例如plan)以及通过命令行指定的参数之前。这种做法确保了环境变量参数优先于通过命令行传递的参数。
例如,执行这样的命令:
1 | TF_CLI_ARGS="-input=false" |
它等价于手工执行
1 | terraform apply -input=false -force |
TF_CLI_ARGS变量影响所有的Terraform命令。如果你只想影响某个特定的子命令,可以使用TF_CLI_ARGS_name变量。例如:
1 | TF_CLI_ARGS_plan="-refresh=false" |
就只会针对plan子命令起作用。该环境变量的值会与通过命令行传入的参数一样被解析,你可以在值里使用单引号和双引号来定义字符串,多个参数之间以空格分隔。
TF_DATA_DIR
TF_DATA_DIR可以修改Terraform保存在每个工作目录下的数据的位置。一般来说,Terraform会把这些数据写入当前工作目录下的.terraform文件夹内,但这一位置可以通过设置TF_DATA_DIR来修改。
大部分情况下我们不应该设置该变量,但有时我们不得不这样做,比如默认路径下我们无权写入数据时。
该数据目录被用来保存下一次执行任意命令时需要读取的数据,所以必须被妥善保存,并确保所有的Terraform命令都可以一致地读写它,否则Terraform会找不到Provider插件、模块代码以及其他文件。
TF_IN_AUTOMATION
如果该变量被设置为非空值,Terraform会意识到自己运行在一个自动化环境下,从而调整自己的输出以避免给出关于该执行什么子命令的建议。这可以使得输出更加一致且减少非必要的信息量。
TF_REGISTRY_DISCOVERY_RETRY
该变量定义了尝试从registry拉取插件或模块代码遇到错误时的重试次数。
TF_REGISTRY_CLIENT_TIMEOUT
该变量定义了发送到registry连接请求的超时时间,默认值为10秒。可以这样设置超时:
1 | export TF_REGISTRY_CLIENT_TIMEOUT=15 |
TF_CLI_CONFIG_FILE
该变量设定了Terraform命令行配置文件的位置:
1 | export TF_CLI_CONFIG_FILE="$HOME/.terraformrc-custom" |
init
todo
plan
apply
Terraform最重要的命令就是apply。apply命令被用来生成执行计划(可选)并执行之,使得基础设施资源状态符合代码的描述。
使用方式
1 | terraform apply [options] [dir-or-plan] |
默认情况下,apply会扫描当前目录下的代码文件,并执行相应的变更。然而,也可以通过参数指定其他代码文件目录。在设计自动化流水线时也可以显式分为创建执行计划、使用apply命令执行该执行计划两个独立步骤。
如果没有显式指定变更计划文件,那么terraform apply会自动创建一个新的变更计划,并提示用户是否批准执行。如果生成的计划不包含任何变更,那么terraform apply会立即退出,不会提示用户输入。
该命令有以下参数可以使用:
-refresh-only:仅刷新,将本地状态文件与云端状态文件保持一直,前提是
terraform plan显示No changes.-backup-path:保存备份文件的路径。默认等于-state-out参数后加上”.backup”后缀。设置为”-“可关闭
-lock=true:执行时是否先锁定状态文件
-input=true:在无法获取输入变量的值是是否提示用户输入
output
todo
console
有时我们想要一个安全的调试工具来帮助我们确认某个表达式是否合法,或者表达式的值是否符合预期,这时我们可以使用terraform console启动一个交互式控制台。
用法
1 | terraform console |
除此之外,还可以在console界面进行当前状态的代码编辑
1 | [root@localhost terraformcode]# terraform console |
指定状态文件位置
1 | terraform console -state=path |
destroy
1 | terraform destroy |
参数
terraform destroy -auto-approve=true,不会征求用户确认直接销毁。
terraform destroy -target
. 只会删除部分资源,例如: 1
terraform destroy -target aws_security_group.allow_all
fmt
terraform fmt命令被用来格式化Terraform代码文件的格式和规范。该命令会对代码文件应用我们之前介绍过的代码风格规范中的一些规定,另外会针对可读性对代码做些微调整。
没使用terraform fmt 之前,代码如下图所示

使用terraform fmt之后

-list=false
不列出包含不一致风格的文件
-diff:展示格式差异

-check:
检查输入是否合规。返回0则代表所有输入的代码风格都是合规,反之则不是0
graph
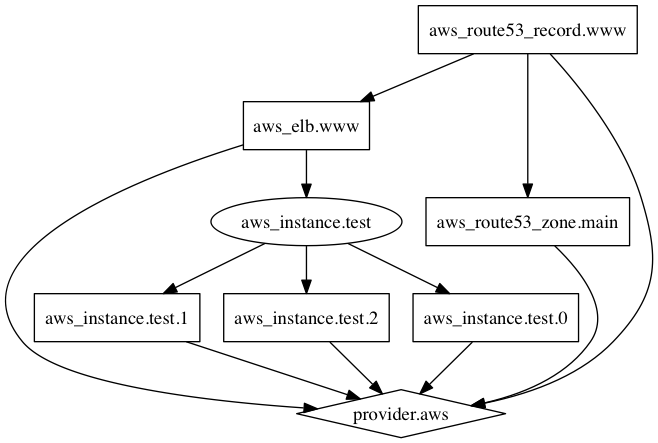
terraform graph命令可以用来生成代码描述的基础设施或是执行计划的可视化图形。它的输出是DOT格式,可以使用GraphViz来生成图片,也有许多网络服务可以读取这种格式。
创建图片文件
terraform graph命令输出的是DOT格式的数据,可以轻松地使用GraphViz转换为图形文件:
1 | terraform graph | dot -Tsvg > graph.svg |
输出的图片大概是这样的:
如何安装GraphViz
安装GraphViz也很简单,对于Ubuntu:
1 | $ sudo apt install graphviz |
对于CentOS:
1 | $ sudo yum install graphviz |
对于Windows,也可以使用choco:
1 | > choco install graphviz |
对于Mac用户:
1 | $ brew install graphviz |
import
terraform import命令用来将已经存在的资源对象导入Terraform。
在使用terraform之前,已经存在基础设施。又或者云资源账户中私自被客户创建了新环境,那么在这种情况下。我们则需要手动将资源对象导入到terraform的状态文件中。
todo
refresh
terraform refresh命令将实际存在的基础设施对象的状态同步到状态文件中记录的对象状态。它可以用来检测真实状态与记录状态之间的漂移并更新状态文件。
警告!!!该命令已在最新版本 Terraform 中被废弃,因为该命令的默认行为在当前用户错误配置了使用的云平台令牌时会引发对状态文件错误的变更。
该命令并不会修改基础设施对象,只修改状态文件。如果状态文件发生改变,将有可能在下次执行plan或apply时引发变更计划。
用法
1 | terraform refresh |
该命令本质上是以下命令的别名,具有完全相同的效果:
terraform apply -refresh-only -auto-approve
主动使用refresh是很危险的,因为如果当前用户错误配置了使用的 Provider 的令牌,那么 Terraform 会错误地以为当前状态文件中记录的所有资源都被删除了,随即从状态文件中无预警地删除所有相关记录。
作为替代我们推荐使用如下命令来取得相同的效果,同时可以在修改状态文件之前预览即将对其作出的修改:
terraform apply -refresh-only
该命令将会在交互界面中提示用户检测到的变更,并提示用户确认执行。
show
terraform show命令从状态文件或是变更计划文件中打印人类可读的输出信息。这可以用来检查变更计划以确定所有操作都是预期的,或是审查当前的状态文件。
Json输出
1 | terraform show -json |
state
terraform state命令可以用来进行复杂的状态管理操作。随着你对Terraform的使用越来越深入,有时候你需要对状态文件进行一些修改。
Aha——会心一击
Terraform使用的是声明式而非命令式的语法,其本身并不是图灵完备的,所以在遇到某些场景时会显得力不从心。
本章我们会介绍一些小技巧以及设计模式和特殊Provider,可以在必要的时候帮助你实现某些特殊的逻辑,起到“会心一击”的效果。
todo